fmt_auto() will automatically apply formatting of various types in a way
that best suits the data table provided. The function will attempt to format
numbers such that they are condensed to an optimal width, either with
scientific notation or large-number suffixing. Currency values are detected
by currency codes embedded in the column name and formatted in the correct
way. Although the functionality here is comprehensive it's still possible to
reduce the scope of automatic formatting with the scope argument and also
by choosing a subset of columns and rows to which the formatting will be applied.
Usage
fmt_auto(
data,
columns = everything(),
rows = everything(),
scope = c("numbers", "currency"),
lg_num_pref = c("sci", "suf"),
locale = NULL
)Arguments
- data
The gt table data object
obj:<gt_tbl>// requiredThis is the gt table object that is commonly created through use of the
gt()function.- columns
Columns to target
<column-targeting expression>// default:everything()Can either be a series of column names provided in
c(), a vector of column indices, or a select helper function (e.g.starts_with(),ends_with(),contains(),matches(),num_range()andeverything()).- rows
Rows to target
<row-targeting expression>// default:everything()In conjunction with
columns, we can specify which of their rows should undergo formatting. The defaulteverything()results in all rows incolumnsbeing formatted. Alternatively, we can supply a vector of row captions withinc(), a vector of row indices, or a select helper function (e.g.starts_with(),ends_with(),contains(),matches(),num_range(), andeverything()). We can also use expressions to filter down to the rows we need (e.g.,[colname_1] > 100 & [colname_2] < 50).- scope
Scope of automatic formatting
mult-kw:[numbers|currency]// default:c("numbers", "currency")By default, the function will format both
"numbers"-type values and"currency"-type values though the scope can be reduced to a single type of value to format.- lg_num_pref
Large-number preference
singl-kw:[sci|suf]// default:"sci"When large numbers are present, there can be a fixed preference toward how they are formatted. Choices are scientific notation for very small and very large values (
"sci"), or, the use of suffixed numbers ("suf", for large values only).- locale
Locale identifier
scalar<character>// default:NULL(optional)An optional locale identifier that can be used for formatting values according to the locale's rules. Examples include
"en"for English (United States) and"fr"for French (France). We can callinfo_locales()for a useful reference for all of the locales that are supported. A locale ID can be also set in the initialgt()function call (where it would be used automatically by any function with alocaleargument) but alocalevalue provided here will override that global locale.
Examples
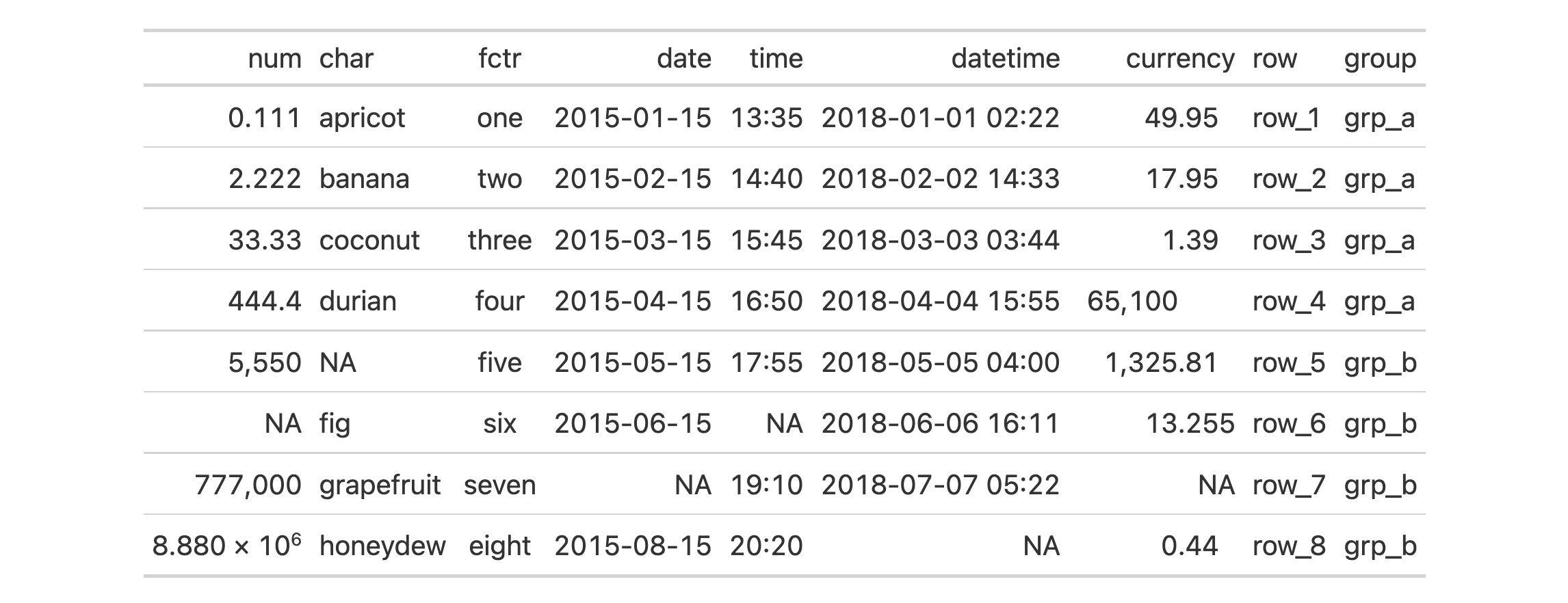
Use the exibble dataset to create a gt table. Format all of the
columns automatically with the fmt_auto() function.
Let's now use the countrypops dataset to create another gt table.
We'll again use fmt_auto() to automatically format all columns but this
time the choice will be made to opt for large-number suffixing instead of
scientific notation. This is done by using the lg_num_pref = "suf" option.
countrypops |>
dplyr::select(country_code_3, year, population) |>
dplyr::filter(country_code_3 %in% c("CHN", "IND", "USA", "PAK", "IDN")) |>
dplyr::filter(year > 1975 & year %% 5 == 0) |>
tidyr::pivot_wider(names_from = year, values_from = population) |>
dplyr::arrange(desc(`2020`)) |>
gt(rowname_col = "country_code_3") |>
fmt_auto(lg_num_pref = "suf")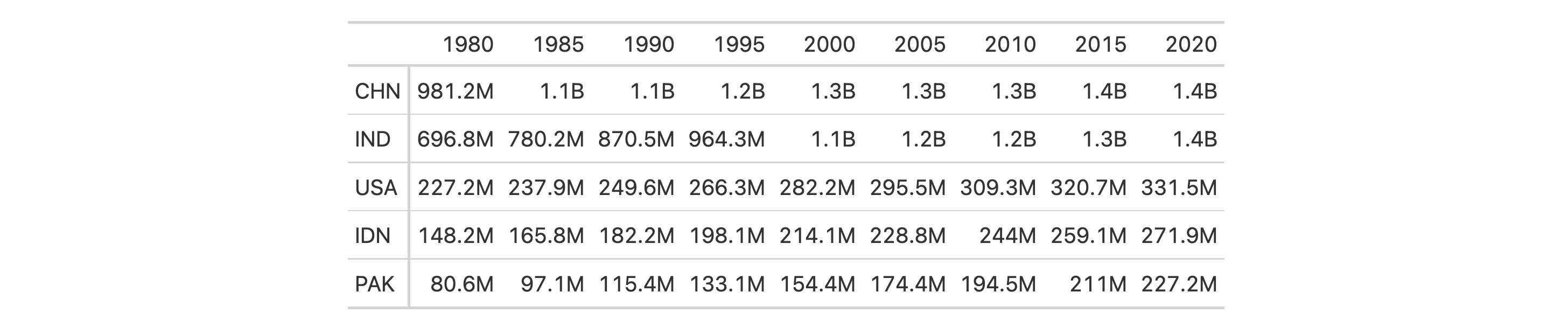
See also
Other data formatting functions:
data_color(),
fmt(),
fmt_bins(),
fmt_bytes(),
fmt_chem(),
fmt_country(),
fmt_currency(),
fmt_date(),
fmt_datetime(),
fmt_duration(),
fmt_email(),
fmt_engineering(),
fmt_flag(),
fmt_fraction(),
fmt_icon(),
fmt_image(),
fmt_index(),
fmt_integer(),
fmt_markdown(),
fmt_number(),
fmt_number_si(),
fmt_partsper(),
fmt_passthrough(),
fmt_percent(),
fmt_roman(),
fmt_scientific(),
fmt_spelled_num(),
fmt_tf(),
fmt_time(),
fmt_units(),
fmt_url(),
sub_large_vals(),
sub_missing(),
sub_small_vals(),
sub_values(),
sub_zero()