With numeric values in a gt table, we can perform number-based formatting so that the targeted values are always rendered as integer values. We can have fine control over integer formatting with the following options:
digit grouping separators: options to enable/disable digit separators and provide a choice of separator symbol
scaling: we can choose to scale targeted values by a multiplier value
large-number suffixing: larger figures (thousands, millions, etc.) can be autoscaled and decorated with the appropriate suffixes
pattern: option to use a text pattern for decoration of the formatted values
locale-based formatting: providing a locale ID will result in number formatting specific to the chosen locale
Usage
fmt_integer(
data,
columns = everything(),
rows = everything(),
use_seps = TRUE,
accounting = FALSE,
scale_by = 1,
suffixing = FALSE,
pattern = "{x}",
sep_mark = ",",
force_sign = FALSE,
min_sep_threshold = 1,
system = c("intl", "ind"),
locale = NULL
)Arguments
- data
The gt table data object
obj:<gt_tbl>// requiredThis is the gt table object that is commonly created through use of the
gt()function.- columns
Columns to target
<column-targeting expression>// default:everything()Can either be a series of column names provided in
c(), a vector of column indices, or a select helper function (e.g.starts_with(),ends_with(),contains(),matches(),num_range()andeverything()).- rows
Rows to target
<row-targeting expression>// default:everything()In conjunction with
columns, we can specify which of their rows should undergo formatting. The defaulteverything()results in all rows incolumnsbeing formatted. Alternatively, we can supply a vector of row captions withinc(), a vector of row indices, or a select helper function (e.g.starts_with(),ends_with(),contains(),matches(),num_range(), andeverything()). We can also use expressions to filter down to the rows we need (e.g.,[colname_1] > 100 & [colname_2] < 50).- use_seps
Use digit group separators
scalar<logical>// default:TRUEAn option to use digit group separators. The type of digit group separator is set by
sep_markand overridden if a locale ID is provided tolocale. This setting isTRUEby default.- accounting
Use accounting style
scalar<logical>// default:FALSEAn option to use accounting style for values. Normally, negative values will be shown with a minus sign but using accounting style will instead put any negative values in parentheses.
- scale_by
Scale values by a fixed multiplier
scalar<numeric|integer>// default:1All numeric values will be multiplied by the
scale_byvalue before undergoing formatting. Since thedefaultvalue is1, no values will be changed unless a different multiplier value is supplied. This value will be ignored if using any of thesuffixingoptions (i.e., wheresuffixingis not set toFALSE).- suffixing
Specification for large-number suffixing
scalar<logical>|vector<character>// default:FALSEThe
suffixingoption allows us to scale and apply suffixes to larger numbers (e.g.,1924000can be transformed to2M). This option can accept a logical value, whereFALSE(the default) will not perform this transformation andTRUEwill apply thousands (K), millions (M), billions (B), and trillions (T) suffixes after automatic value scaling.We can alternatively provide a character vector that serves as a specification for which symbols are to be used for each of the value ranges. These preferred symbols will replace the defaults (e.g.,
c("k", "Ml", "Bn", "Tr")replaces"K","M","B", and"T").Including
NAvalues in the vector will ensure that the particular range will either not be included in the transformation (e.g.,c(NA, "M", "B", "T")won't modify numbers at all in the thousands range) or the range will inherit a previous suffix (e.g., withc("K", "M", NA, "T"), all numbers in the range of millions and billions will be in terms of millions).Any use of
suffixing(where it is not set expressly asFALSE) means that any value provided toscale_bywill be ignored.If using
system = "ind"then the default suffix set provided bysuffixing = TRUEwill be the equivalent ofc(NA, "L", "Cr"). This doesn't apply suffixes to the thousands range, but does express values in lakhs and crores.- pattern
Specification of the formatting pattern
scalar<character>// default:"{x}"A formatting pattern that allows for decoration of the formatted value. The formatted value is represented by the
{x}(which can be used multiple times, if needed) and all other characters will be interpreted as string literals.- sep_mark
Separator mark for digit grouping
scalar<character>// default:","The string to use as a separator between groups of digits. For example, using
sep_mark = ","with a value of1000would result in a formatted value of"1,000". This argument is ignored if alocaleis supplied (i.e., is notNULL).- force_sign
Forcing the display of a positive sign
scalar<logical>// default:FALSEShould the positive sign be shown for positive values (effectively showing a sign for all values except zero)? If so, use
TRUEfor this option. The default isFALSE, where only negative numbers will display a minus sign. This option is disregarded when using accounting notation withaccounting = TRUE.- min_sep_threshold
Minimum digit threshold for grouping separators
scalar<numeric|integer>(val>=1)// default:1The minimum number of digits required in the integer part of a number for grouping separators to be applied. This parameter determines when digit grouping begins based on the magnitude of values. The value
1(the default) applies separators starting at 4-digit numbers (e.g.,1,000and above). A value of2starts grouping at 5-digit numbers (10,000and above), while3begins at 6-digit numbers (100,000and above).- system
Numbering system for grouping separators
singl-kw:[intl|ind]// default:"intl"The international numbering system (keyword:
"intl") is widely used and its grouping separators (i.e.,sep_mark) are always separated by three digits. The alternative system, the Indian numbering system (keyword:"ind"), uses grouping separators that correspond to thousand, lakh, crore, and higher quantities.- locale
Locale identifier
scalar<character>// default:NULL(optional)An optional locale identifier that can be used for formatting values according to the locale's rules. Examples include
"en"for English (United States) and"fr"for French (France). We can callinfo_locales()for a useful reference for all of the locales that are supported. A locale ID can be also set in the initialgt()function call (where it would be used automatically by any function with alocaleargument) but alocalevalue provided here will override that global locale.
Compatibility of formatting function with data values
fmt_integer() is compatible with body cells that are of the "numeric",
"integer", or "integer64" types. Any other types of body cells are
ignored during formatting. This is to say that cells of incompatible data
types may be targeted, but there will be no attempt to format them.
Compatibility of arguments with the from_column() helper function
from_column() can be used with certain arguments of fmt_integer() to
obtain varying parameter values from a specified column within the table.
This means that each row could be formatted a little bit differently. These
arguments provide support for from_column():
use_sepsaccountingscale_bysuffixingpatternsep_markforce_signmin_sep_thresholdsystemlocale
Please note that for all of the aforementioned arguments, a from_column()
call needs to reference a column that has data of the correct type (this is
different for each argument). Additional columns for parameter values can be
generated with cols_add() (if not already present). Columns that contain
parameter data can also be hidden from final display with cols_hide().
Finally, there is no limitation to how many arguments the from_column()
helper is applied so long as the arguments belong to this closed set.
Adapting output to a specific locale
This formatting function can adapt outputs according to a provided locale
value. Examples include "en" for English (United States) and "fr" for
French (France). The use of a valid locale ID here means separator marks will
be correct for the given locale. Should any value be provided in sep_mark,
it will be overridden by the locale's preferred value.
Note that a locale value provided here will override any global locale
setting performed in gt()'s own locale argument (it is settable there as
a value received by all other functions that have a locale argument). As a
useful reference on which locales are supported, we can call info_locales()
to view an info table.
Examples
For this example, we'll use two columns from the exibble dataset and
create a simple gt table. With fmt_integer(), we'll format the num
column as integer values having no digit separators (with the
use_seps = FALSE option).
exibble |>
dplyr::select(num, char) |>
gt() |>
fmt_integer(use_seps = FALSE)
Let's use a modified version of the countrypops dataset to create a
gt table with row labels. We will format all numeric columns with
fmt_integer() and scale all values by 1 / 1E6, giving us integer values
representing millions of people. We can make clear what the values represent
with an informative spanner label via tab_spanner().
countrypops |>
dplyr::select(country_code_3, year, population) |>
dplyr::filter(country_code_3 %in% c("CHN", "IND", "USA", "PAK", "IDN")) |>
dplyr::filter(year > 1975 & year %% 5 == 0) |>
tidyr::pivot_wider(names_from = year, values_from = population) |>
dplyr::arrange(desc(`2015`)) |>
gt(rowname_col = "country_code_3") |>
fmt_integer(scale_by = 1 / 1E6) |>
tab_spanner(label = "Millions of People", columns = everything())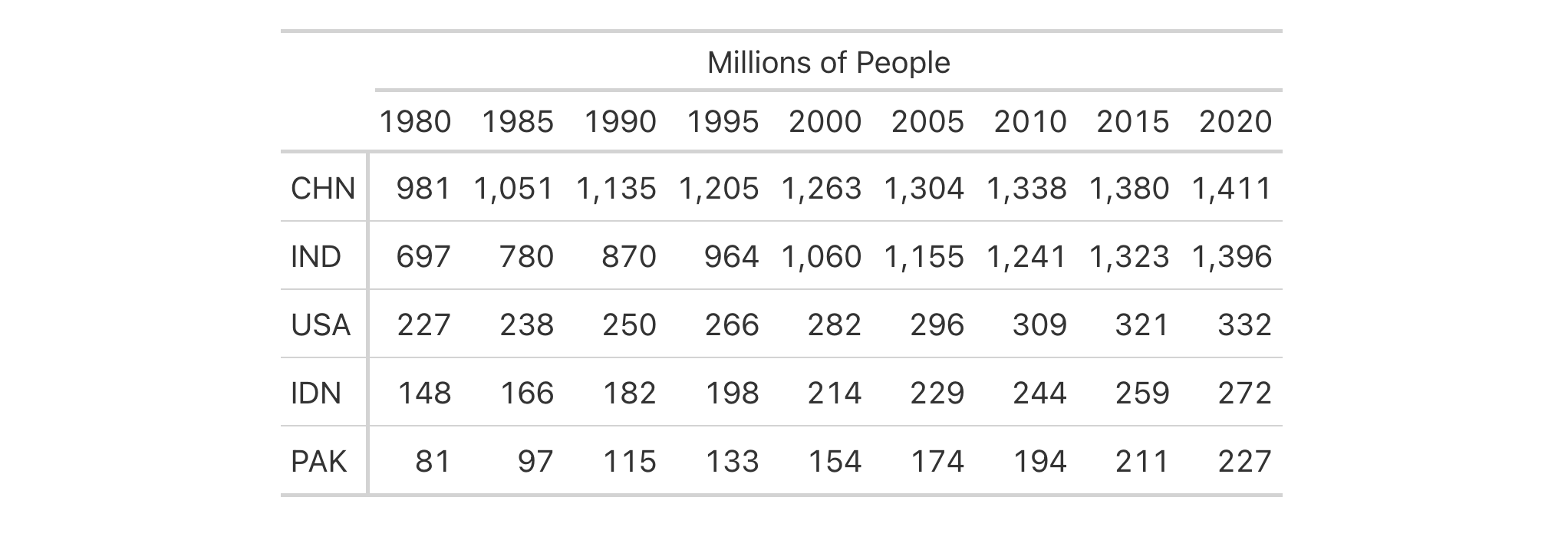
Using a subset of the towny dataset, we can do interesting things with
integer values. Through cols_add() we'll add the difference column (which
calculates the difference between 2021 and 2001 populations). All numeric
values will be formatted with a first pass of fmt_integer(); a second pass
of fmt_integer() focuses on the difference column and here we use the
force_sign = TRUE option to draw attention to positive and negative
difference values.
towny |>
dplyr::select(name, population_2001, population_2021) |>
dplyr::slice_tail(n = 10) |>
gt() |>
cols_add(difference = population_2021 - population_2001) |>
fmt_integer() |>
fmt_integer(columns = difference, force_sign = TRUE) |>
cols_label_with(fn = function(x) gsub("population_", "", x)) |>
tab_style(
style = cell_fill(color = "gray90"),
locations = cells_body(columns = difference)
)
See also
Format number with decimal values: fmt_number()
The vector-formatting version of this function: vec_fmt_integer()
Other data formatting functions:
data_color(),
fmt(),
fmt_auto(),
fmt_bins(),
fmt_bytes(),
fmt_chem(),
fmt_country(),
fmt_currency(),
fmt_date(),
fmt_datetime(),
fmt_duration(),
fmt_email(),
fmt_engineering(),
fmt_flag(),
fmt_fraction(),
fmt_icon(),
fmt_image(),
fmt_index(),
fmt_markdown(),
fmt_number(),
fmt_number_si(),
fmt_partsper(),
fmt_passthrough(),
fmt_percent(),
fmt_roman(),
fmt_scientific(),
fmt_spelled_num(),
fmt_tf(),
fmt_time(),
fmt_units(),
fmt_url(),
sub_large_vals(),
sub_missing(),
sub_small_vals(),
sub_values(),
sub_zero()